


.png)

Every british marketer aiming for accurate website tracking faces one critical challenge: keeping data consistent and actionable across multiple platforms. With over 60 percent of analytics errors traced to misconfigured data layers, overlooking this foundation can derail digital campaigns and compliance efforts. Understanding the data layer’s role is essential for anyone using Google Tag Manager because it ensures that valuable user insights are captured, shared, and protected throughout your analytics stack.
Table of Contents
- Defining The Data Layer In Google Tag Manager
- Types Of Data Layers And Their Key Differences
- How Data Layer Powers Server-Side Tagging
- Implementing Consent Management And GDPR Compliance
- Common Mistakes And How To Avoid Data Loss
Key Takeaways
| Point | Details |
|---|---|
| Importance of Data Layer | The data layer is essential for transmitting accurate information between websites and analytics platforms, enhancing data tracking precision. |
| Types of Data Layers | Understanding static, dynamic, and hybrid data layers helps tailor tracking strategies to meet specific organisational needs. |
| Consent Management | Implementing a robust consent framework within the data layer ensures compliance with GDPR and enhances user privacy. |
| Avoiding Data Loss | Consistent variable management and thorough validation protocols are critical to prevent data loss and ensure reliable analytics. |
Defining the Data Layer in Google Tag Manager
A data layer serves as a critical communication bridge in digital tracking, functioning as a dynamic JavaScript object that enables seamless data transfer between websites and analytics platforms. Developers from Google describe it as a fundamental mechanism for passing website information to tags, allowing precise triggering and tracking of user interactions.
At its core, the data layer acts like an intelligent routing system, collecting and standardising various website events and user interactions before transmitting them to marketing and analytics tools. Digital analytics experts highlight that this central repository transforms raw website interactions into structured, actionable data, making it possible to track everything from page views to complex conversion funnels with unprecedented accuracy.
The technical architecture of a data layer typically involves storing key information such as page type, user attributes, transaction details, and custom event parameters. These data points are organised in a consistent, hierarchical format that Google Tag Manager can easily interpret and distribute across multiple tracking platforms. This standardisation ensures that different marketing technologies receive uniform, clean data without requiring complex custom integrations for each individual tool.
Pro Tip: Data Layer Optimisation: Always initialise your data layer before any tracking scripts load, and consistently push updated information using standardised event naming conventions to maximise tracking precision and reduce potential data discrepancies.
Types of Data Layers and Their Key Differences
Data layers represent a sophisticated approach to digital tracking, with multiple implementation strategies tailored to diverse organisational requirements. Analytics experts highlight that these JavaScript objects can be structured in various ways, each offering unique capabilities for capturing and routing website interaction data.
Primarily, data layers can be categorised into three fundamental types: static, dynamic, and hybrid. Static data layers contain predefined, fixed information that remains consistent across page loads, such as website domain or global user preferences. Dynamic data layers, conversely, continuously update with real-time user interactions, capturing granular details like product views, cart additions, and transaction specifics. Hybrid data layers combine these approaches, providing a flexible framework that maintains some static elements while allowing dynamic information updates.
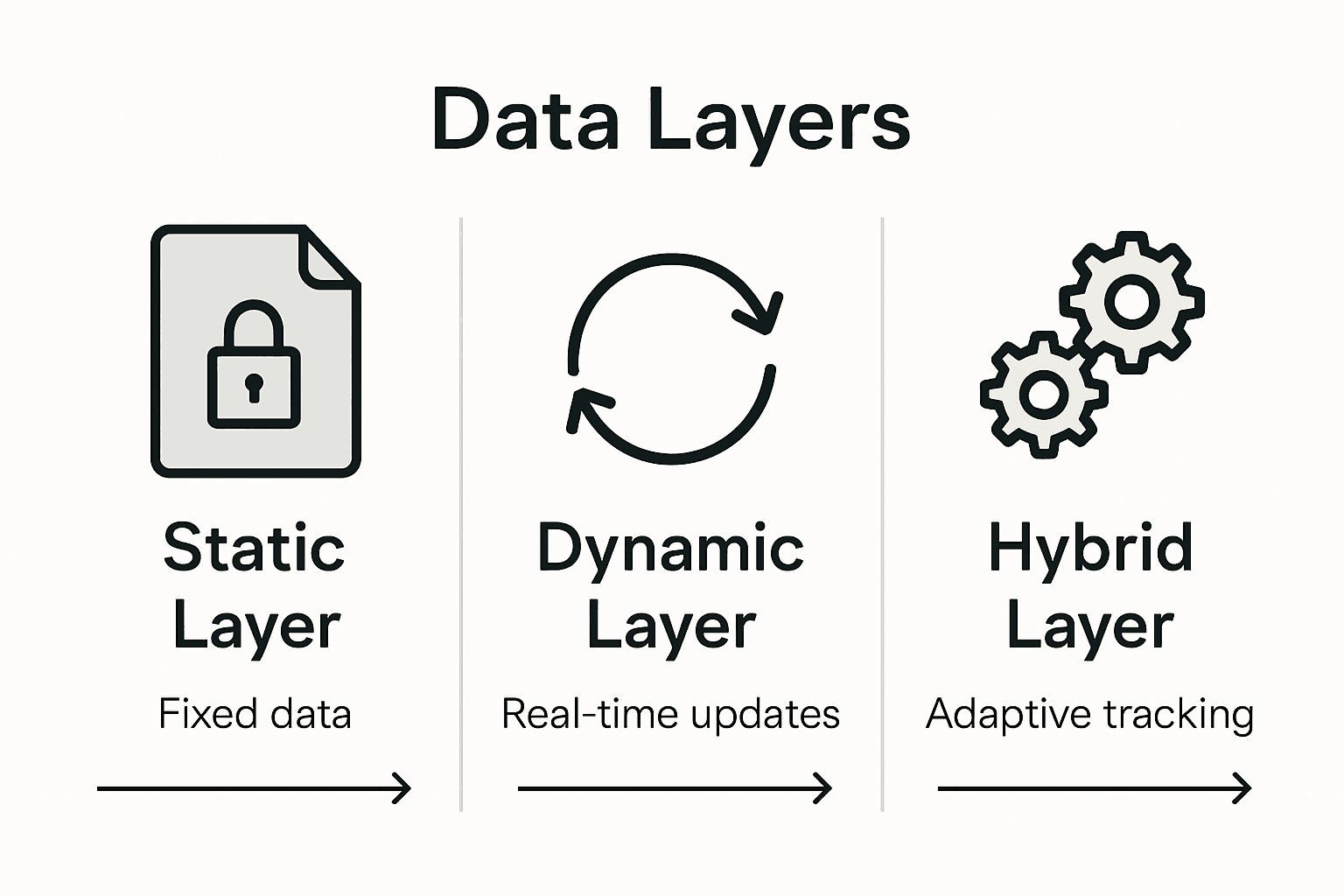
The architectural differences between these data layer types significantly impact tracking precision and marketing analytics capabilities. Static implementations offer simplicity and predictability, making them ideal for websites with relatively unchanging user journeys. Dynamic data layers provide superior granularity, enabling marketers to capture nuanced user behaviour patterns across complex digital environments. Hybrid models represent the most sophisticated approach, offering a balanced method that adapts to varying tracking requirements while maintaining consistent data structure.
Here is a comparison of common data layer types and their ideal use cases:
| Data Layer Type | Example Use Case | Key Benefits |
|---|---|---|
| Static | Corporate site with few changes | Easy to implement, highly predictable |
| Dynamic | E-commerce checkout tracking | Captures real-time user behaviour |
| Hybrid | News sites with custom user settings | Balances flexibility and structure |
Pro Tip: Data Layer Configuration: When designing your data layer, prioritise a standardised naming convention and consistent data structure to ensure seamless integration across different analytics and marketing platforms, reducing potential tracking inconsistencies.
How Data Layer Powers Server-Side Tagging
Server-side tagging represents a sophisticated evolution in digital tracking, with the data layer serving as its fundamental architectural backbone. Google developers explain that the data layer functions as a structured JSON object, meticulously capturing event names, variable values, and critical tracking information that enables seamless server-side data transmission.

The mechanism of powering server-side tagging through the data layer involves a complex yet elegant process of data aggregation and standardisation. By creating a centralised repository of user interactions, the data layer enables marketing technologies to access consistent, clean information without direct client-side dependencies. Analytics experts highlight that this approach dramatically improves data accuracy, reduces tracking vulnerabilities, and provides a more robust method of collecting user behaviour insights across multiple platforms.
In practice, server-side tagging powered by data layers allows organisations to implement advanced tracking strategies that transcend traditional client-side limitations. This approach enables precise event tracking, enhanced privacy controls, and the ability to process complex data transformations before transmission to analytics platforms. By decoupling data collection from immediate client-side execution, businesses can implement more sophisticated tracking logic, reduce page load times, and maintain greater control over their digital analytics infrastructure.
Pro Tip: Server-Side Tracking Optimisation: Design your data layer with comprehensive, consistent variable naming conventions and implement robust error handling mechanisms to ensure reliable data transmission and minimise potential tracking interruptions.
Implementing Consent Management and GDPR Compliance
Navigating the complex landscape of data privacy requires sophisticated approaches to consent management, particularly within e-commerce platforms. Research on tag management systems reveals that data layers can be strategically leveraged to manage user consent preferences, enabling precise control over data collection processes that align with stringent regulatory requirements.
The implementation of a robust consent management framework through data layers involves creating granular consent mechanisms that provide users with transparent choices about their data usage. Analytics experts emphasise the importance of establishing a centralised data handling structure that allows organisations to capture, store, and respect individual user consent preferences. This approach enables businesses to dynamically adjust tracking behaviours based on explicit user permissions, ensuring compliance with GDPR’s fundamental principles of data transparency and user autonomy.
Practical implementation requires a multi-layered approach that integrates consent signals directly into the data layer architecture. This means developing sophisticated trigger mechanisms that conditionally fire tags only when appropriate user consent has been obtained, effectively creating a permission-based tracking ecosystem. By embedding consent management directly into the data layer, organisations can create a seamless, user-centric approach to data collection that respects individual privacy while maintaining comprehensive analytics capabilities.
Pro Tip: Consent Configuration: Develop a modular consent framework within your data layer that allows granular opt-in/opt-out controls for different categories of data processing, enabling users to make informed, precise choices about their personal information.
Common Mistakes and How to Avoid Data Loss
Data layer tracking demands meticulous attention to prevent critical information loss and ensure accurate analytics performance. Google developers recommend that data layer variables must be systematically pushed on each page load, strategically positioning the code above the Google Tag Manager container to guarantee immediate data availability and reduce potential tracking interruptions.
Common pitfalls in data layer implementation often stem from inconsistent variable management and structural complexity. Analytics experts highlight several fundamental mistakes that can compromise data integrity, including inconsistent variable naming conventions, improper casing, and unintentional overwrites of the primary data layer object. These seemingly minor technical oversights can create significant tracking discrepancies, potentially leading to incomplete or misleading analytics insights.
Mitigating data loss requires a comprehensive approach that combines technical precision with strategic implementation. E-commerce businesses must develop robust validation mechanisms that continuously monitor data layer integrity, ensuring that critical user interaction data remains consistent and accurately captured across complex digital environments. This involves implementing sophisticated error handling protocols, creating redundant data capture strategies, and regularly auditing tracking configurations to identify and rectify potential vulnerabilities.
To help avoid data loss in analytics, consider these best practice checkpoints:
| Risk Area | Consequence | Prevention Strategy |
|---|---|---|
| Inconsistent variable names | Data gets misattributed or lost | Use strict naming conventions |
| Delayed data layer initialisation | Missing critical events | Initialise data layer before scripts |
| Object overwrites | Loss of previous data pushes | Use push method, avoid direct reassign |
Pro Tip: Data Layer Validation: Establish automated testing protocols that validate data layer object structures before tag firing, ensuring consistent data formatting and preventing potential tracking interruptions across different user journeys and website interactions.
Master Your E-Commerce Tracking with Advanced Data Layer Solutions
Tracking inaccuracies and data loss from traditional analytics tools can severely hinder your e-commerce growth. The article highlights common challenges such as inconsistent data layer configurations, delayed initialisations, and the complexities of consent management under GDPR. These pain points lead to unreliable conversion tracking and limited insights into user behaviour, risking lost revenue and ineffective marketing spend.
AdPage offers a powerful platform tailored to solve these exact problems through robust server-side tagging and consent management systems. Our solution ensures 100% accurate data collection by optimising your data layer setup, preventing lost events, and automating consent-driven tracking compliance. Whether you run Shopify, WooCommerce, or Magento stores, our seamless integration and expert onboarding simplify complex analytics, empowering marketing agencies and online marketers to make faster, data-driven decisions.
Explore how AdPage can transform your tracking and gain the confidence that every user interaction is captured flawlessly.
Ready to elevate your conversion tracking and secure GDPR compliance with ease Visit AdPage today and start maximising your e-commerce performance through precise, reliable data insights.
Frequently Asked Questions
What is a data layer in Google Tag Manager?
A data layer in Google Tag Manager is a dynamic JavaScript object that acts as a communication bridge, enabling the transfer of data between your website and analytics platforms for precise tracking of user interactions.
How can I optimise my data layer for better e-commerce tracking?
To optimise your data layer, initialise it before any tracking scripts load and consistently push updated information using standardised naming conventions to enhance tracking precision and reduce discrepancies.
What are the differences between static, dynamic, and hybrid data layers?
Static data layers contain fixed information across page loads, dynamic data layers capture real-time user interactions, and hybrid data layers combine both approaches, allowing flexibility while maintaining consistent data structure.
How does server-side tagging improve data accuracy in e-commerce analytics?
Server-side tagging enhances data accuracy by aggregating user interactions into a centralised structure, enabling cleaner data transmission without client-side dependencies, thus reducing tracking vulnerabilities.